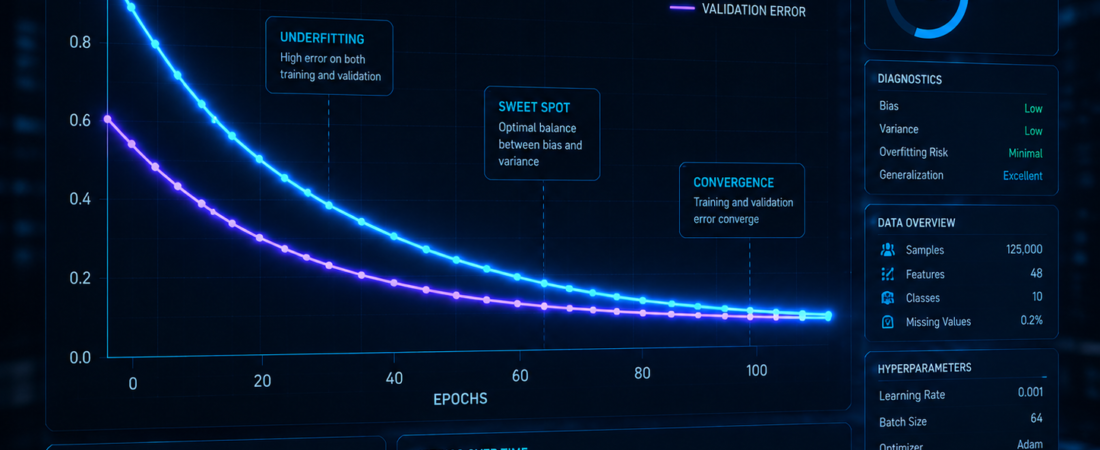
Cuando un equipo de investigación entrena un modelo de inteligencia artificial, ¿cómo saben si está realmente mejorando o simplemente memorizando los datos sin desarrollar capacidades genuinas? La curva de aprendizaje de máquinas es la herramienta diagnóstica fundamental que los científicos de datos usan para responder esta pregunta crítica durante el desarrollo de cualquier modelo de machine learning.
Qué es la curva de aprendizaje de máquinas y por qué es tan importante
La curva de aprendizaje de máquinas es una representación gráfica que muestra cómo evoluciona el rendimiento de un modelo a medida que se entrena con más datos o durante más iteraciones de entrenamiento, comparando típicamente el rendimiento en los datos de entrenamiento con el rendimiento en datos de validación nunca vistos por el modelo.
Esta herramienta diagnóstica es fundamental porque revela información que las métricas de rendimiento final, por sí solas, no pueden mostrar: si el modelo está aprendiendo de forma saludable, si necesita más datos, si está memorizando en lugar de generalizar, o si ha alcanzado un punto donde más entrenamiento ya no produce mejoras significativas.
Cómo interpretar los patrones en la curva de aprendizaje de máquinas
Una curva de aprendizaje de máquinas saludable muestra que tanto el error de entrenamiento como el error de validación disminuyen progresivamente y convergen hacia valores similares y bajos, indicando que el modelo está aprendiendo patrones generales que funcionan tanto en los datos que ha visto como en datos nuevos.
Cuando la curva de aprendizaje de máquinas muestra un error de entrenamiento muy bajo pero un error de validación significativamente más alto, y la brecha entre ambos se mantiene o crece, esto indica overfitting: el modelo está memorizando particularidades de los datos de entrenamiento en lugar de aprender patrones generalizables.
Cuando tanto el error de entrenamiento como el de validación permanecen altos y no mejoran significativamente con más datos, esto sugiere underfitting: el modelo es demasiado simple para capturar la complejidad real del problema, independientemente de cuántos datos adicionales se proporcionen.
Los usos prácticos de la curva de aprendizaje de máquinas
Decidir si recopilar más datos vale la pena
Una de las preguntas más costosas en cualquier proyecto de machine learning es si invertir recursos significativos en recopilar más datos de entrenamiento mejorará realmente el modelo. La curva de aprendizaje de máquinas, extrapolando su tendencia, puede sugerir si el rendimiento seguiría mejorando con más datos o si ya se ha alcanzado un punto de rendimientos decrecientes donde el esfuerzo adicional no justificaría la inversión.
Diagnosticar problemas de arquitectura del modelo
Si la curva de aprendizaje de máquinas muestra un estancamiento prematuro en niveles de rendimiento insatisfactorios, esto puede indicar que la arquitectura del modelo es demasiado simple para el problema, sugiriendo la necesidad de una arquitectura más compleja o de características adicionales que capturen mejor la información relevante del problema.
Determinar cuándo detener el entrenamiento
La técnica de early stopping, fundamental para evitar el overfitting, se basa directamente en monitorizar la curva de aprendizaje de máquinas durante el entrenamiento y detenerlo en el punto donde el rendimiento de validación empieza a degradarse, incluso si el rendimiento de entrenamiento sigue mejorando. Puedes explorar implementaciones prácticas de curvas de aprendizaje en la documentación de scikit-learn en scikit-learn.org/stable/modules/learning_curve.html.
Las limitaciones de interpretar la curva de aprendizaje de máquinas
Aunque extraordinariamente útil, la curva de aprendizaje de máquinas no captura todos los aspectos relevantes del rendimiento de un modelo. Un modelo puede mostrar una curva de aprendizaje saludable en términos de precisión general pero tener un rendimiento muy desigual entre diferentes subgrupos de datos, lo que requiere análisis adicionales de equidad y rendimiento desagregado más allá de lo que muestra esta herramienta diagnóstica básica.
Conclusión
La curva de aprendizaje de máquinas es una de las herramientas diagnósticas más fundamentales en el desarrollo responsable de modelos de inteligencia artificial, permitiendo a los científicos de datos tomar decisiones informadas sobre cuándo un modelo está listo, cuándo necesita ajustes y cuándo simplemente necesita más datos de entrenamiento.
Entender esta herramienta, aunque técnica, ayuda a comprender mejor el proceso real detrás del desarrollo de los sistemas de IA que usamos cada día. En ExplicaIA seguimos explicando los fundamentos técnicos de la inteligencia artificial con el rigor que merecen.